AI 视频生成正从简单的短片创作演进为支持长时长、高物理一致性的工业级流程。截至 2026 年 3 月,该领域的核心矛盾已从追求“画面真实度”转移到“物理逻辑可控性”与“版权合规性”。
目前的顶级模型如 Sora 2、Kling 2.6 和 Wan 2.6 虽然能模拟复杂的流体动力学和光影折射,但要达到商业广告或电影正片的工业标准,依然高度依赖复杂的提示词工程和后期引导。AI 视频并非简单的滤镜叠加,而是一场关于现实物理规律模拟的竞赛。
技术原理解析:从潜在扩散到时空注意力机制
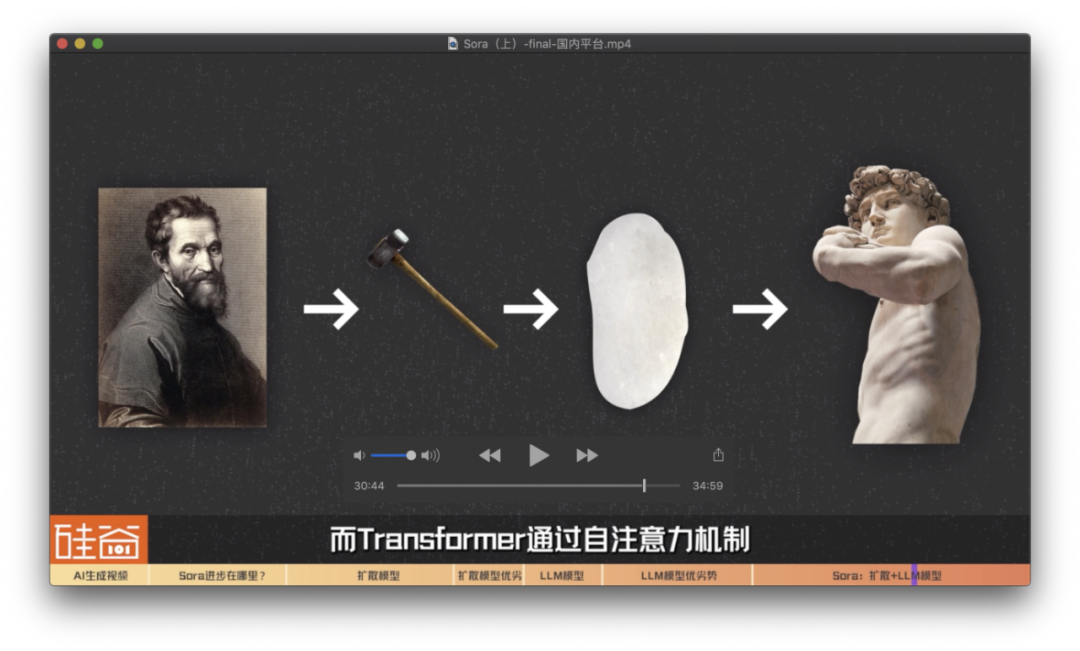
现代 AI 视频生成在压缩的潜在空间(Latent Space)中进行去噪。主流模型采用 DiT(Diffusion Transformer)架构,将视频切分为时空补丁(Spacetime Patches)。Transformer 通过注意力机制计算这些补丁之间的关系,从而维持人物在不同帧中的面部一致性并模拟物理惯性。
这种机制显著减轻了早期的“闪烁”问题。但模型依然频繁出现“幻觉”——例如行走时腿部融合或液体违背重力。这证明 AI 并不真正理解物理定律,而是在基于海量数据预测像素的出现概率。
商业级短片实操指南
想要获得商业级成品,不能依赖单次提示词生成,而应建立“素材生成 $\rightarrow$ 结构控制 $\rightarrow$ 精细化编辑”的流水线。
第一步:结构化描述与种子值锁定
可控画面需采用“环境 + 主体 + 动作 + 镜头语言 + 光影参数”的结构,而非简单的描述。例如:
- 环境:2026 年东京街头,雨后霓虹灯反射,8k 超高清,电影级宽画幅。
- 主体:身穿黑色防水风衣的男人,面部有细微雨滴。
- 镜头:低角度跟拍,推拉镜头,焦距 35mm。
第二步:图生视频(Image-to-Video)精准控制
最稳健的路径是先用 Midjourney 或 Flux 生成静态底图,再导入视频模型激活,以降低随机性。
第三步:局部重绘(Inpainting)细节修正
当视频氛围正确但细节错误时,使用局部重绘而非重新生成。在 Seed Edit 或 HAILUO 界面中,选定错误时间段并涂抹物体(如多出的一根手指),输入修正提示词。
主流工具对比与场景选择

| 工具类别 | 代表模型/工具 | 核心优势 | 适用场景 |
|---|---|---|---|
| 电影级模拟 | Sora 2, Kling 2.6, Wan 2.6 | 强时空一致性, 复杂物理模拟 | 概念片, 电影短片 |
| 电商出片 | Tagshop AI, Nano Banana Pro | 快速转化, 低成本, 无需复杂提示词 | 亚马逊广告, 产品短视频 |
| 专业控制 | SEED DANCE, HAILUO | 支持路径追踪, 骨架图驱动 | 导演级精细剪辑 |
风险提醒与技术局限
目前 AI 视频存在三个难以逾越的边界:
- 复杂交互失效:系鞋带、剥鸡蛋等精细物理碰撞极易导致物体融合。
- 长文本逻辑断层:单次生成超过 1 分钟后,常出现场景漂移或服装细节改变。
- 情感表达空洞:无法模拟情感递进,所谓的“深情”往往只是慢动作和光影的堆砌。
若项目需要极高的品牌资产精确度(如工业设计的 R 角)或极精细的人机交互,AI 视频目前无法替代真人拍摄或 3D 建模。
工作流升级路径
不建议盲目追求单一工具,而应构建异构工具链。个人创作者可尝试以下链路:
Flux (底图) -> Kling 2.6 (动态) -> Topaz Video AI (增强) -> CapCut (剪辑)Flux (底图) -> Kling 2.6 (动态) -> Topaz Video AI (增强) -> CapCut (剪辑)
小型工作室应引入版本控制,为每个镜头的种子值、提示词和参考图建立索引库,通过回溯种子值在 Seed Edit 中统一细节,而非整体重来。
2026 下半年趋势展望
未来的突破口在于“实时生成”与“物理引擎集成”。视频生成可能从异步等待变为实时响应,允许用户像操作 3D 软件一样通过拖拽改变焦距或位置。
同时,音频与视频的同步将从简单的口型同步演变为情绪同步,使光影闪烁与呼吸频率自动匹配音乐节奏。
如何有效解决 AI 视频中的“肢体融合”现象?
建议采用“图生视频”链路,通过锁定底图结构来维持形体,并配合局部重绘(Inpainting)对错误帧进行低强度(0.3-0.5)的去噪修正,而非完全依赖文本生成。
种子值(Seed)在视频生成中究竟起什么作用?
种子值决定了随机噪声的初始分布。在相同模型和提示词下,固定种子值可以保持画面基调和主体特征的一致性,是实现分镜连续性的技术核心。
目前 AI 视频能完全替代 3D 建模吗?
不能。对于需要极高几何精度(如工业产品 R 角)或精确物理碰撞模拟的场景,3D 建模具有绝对的确定性,而 AI 视频目前仍处于“概率预测”阶段。
行动建议:不要执着于寻找“完美提示词”,因为这只是过渡方案。建议学习拆解分镜、定义光影和把控剪辑节奏。你可以尝试将现有的一个 15 秒产品短片用“图生视频”链路重新制作,感受从静态到动态的控制落差,这比阅读文档更有效。